Wednesday, February 19th 2025

AMD Ryzen AI Max+ "Strix Halo" Die Exposed and Annotated
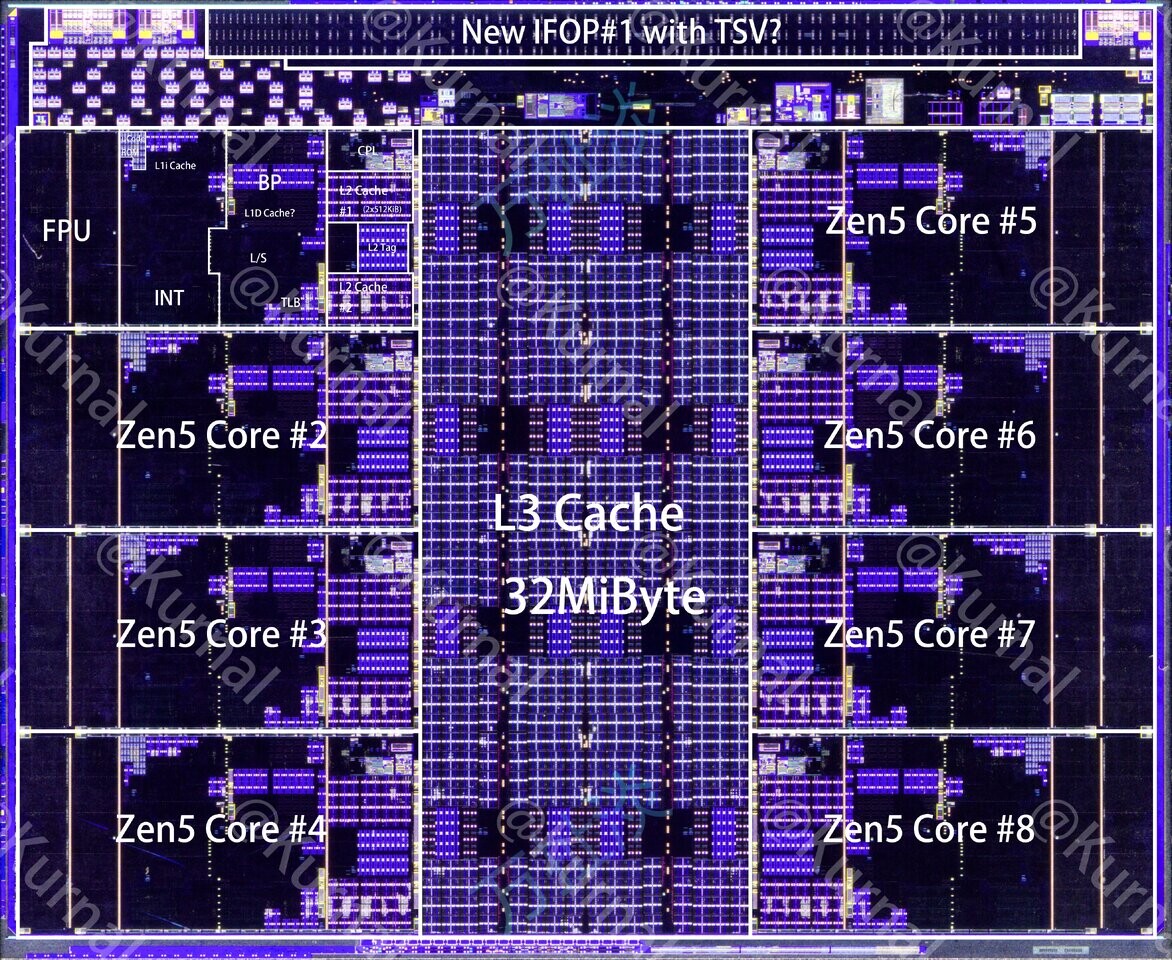
AMD's "Strix Halo" APU, marketed as Ryzen AI Max+, has just been exposed in die-shot analysis. Confirming the processor's triple-die architecture, the package showcases a total silicon footprint of 441.72 mm² that integrates advanced CPU, GPU, and AI acceleration capabilities within a single package. The processor's architecture centers on two 67.07 mm² CPU CCDs, each housing eight Zen 5 cores with a dedicated 8 MB L2 cache. A substantial 307.58 mm² I/O complements these die that houses an RDNA 3.5-based integrated GPU featuring 40 CUs and AMD's XDNA 2 NPU. The memory subsystem demonstrates a 256-bit LPDDR5X interface capable of delivering 256 GB/s bandwidth, supported by 32 MB of strategically placed Last Level Cache to optimize data throughput.
The die shots reveal notable optimizations for mobile deployment, including shortened die-to-die interfaces that reduce the interconnect distance by 2 mm compared to desktop implementations. Some through-silicon via structures are present, which suggest potential compatibility with AMD's 3D V-Cache technology, though the company has not officially confirmed plans for such implementations. The I/O die integrates comprehensive connectivity options, including PCIe 4.0 x16 lanes and USB4 support, while also housing dedicated media engines with full AV1 codec support. Initial deployments of the Strix Halo APU will commence with the ASUS ROG Flow Z13 launch on February 25, marking the beginning of what AMD anticipates will be broad adoption across premium mobile computing platforms.


Sources:
Tony Yu on Bilibili, Kurnal on X, via Tom's Hardware
The die shots reveal notable optimizations for mobile deployment, including shortened die-to-die interfaces that reduce the interconnect distance by 2 mm compared to desktop implementations. Some through-silicon via structures are present, which suggest potential compatibility with AMD's 3D V-Cache technology, though the company has not officially confirmed plans for such implementations. The I/O die integrates comprehensive connectivity options, including PCIe 4.0 x16 lanes and USB4 support, while also housing dedicated media engines with full AV1 codec support. Initial deployments of the Strix Halo APU will commence with the ASUS ROG Flow Z13 launch on February 25, marking the beginning of what AMD anticipates will be broad adoption across premium mobile computing platforms.


11 Comments on AMD Ryzen AI Max+ "Strix Halo" Die Exposed and Annotated
It looks like they are trialing this interconnect on Strix Halo and they will implement it across Zen6 chiplets and IOD as a new high-bandwidth, low latency and high-efficiency interconnect standard. Quite exciting, indeed.
Some modern GPUs have USB-C port as an interface for DP video signal, and not for carrying USB or PCIe data.
On Strix Halo IOD, USB3 and USB4 PHY are additional pieces of logic, as well as NPU, which are not present on GPU die.
It took them four iterations to come to this maximum size design for the package used. It's better to have such product in the market than wait another year or so for yet another lab chip iteration to be perfected. It's more practical the way it is.Final MI300 is CoWoS-S, though they did have CoWoS-R as test chip. Navi 31 uses InFO-R/oS packaging with 4 RDL layers.
semianalysis.com/2023/06/12/amd-mi300-taming-the-hype-ai-performance/
For Strix Halo, we don't know, until we know. It's either InFO-R or InFO-L, or another interation.